Command and Query Responsibility Segregation (CQRS) Pattern
Das CQRS-Pattern führt eine Teilung zwischen den data transfer objects (DTO) ein, sodass das Schreiben von Daten (Command) und Lesen von Daten (Query) über zwei verschiedene Interfaces -
respektive DTOs - geschieht.
Problemstellung
Klassisch geschehen alle Schreib- und Leseoperationen auf ein Entitiy (in der Datenbank) über ein und das selbe DTO und dabei wird immer mit ein und der selben Datenbank kommuniziert.
Das heißt, alle CRUD-Operationen haben das selbe Zielobjekt. Zum Beispiel wird ein Kunden-DTO über den data access layer (DAL) angefordert und auf dem Bildschirm angezeigt. Ein Nutzer
der Applikation aktualisiert nun einige Felder des Kunden-DTO und speichert. Die Applikation wird nun diesen DTO über den DAL auf die Datenbank speichern. Ein DTO wurde also sowohl für das Lesen,
als auch für das Schreiben genutzt.
Diese Art und Weise mit den CRUD-Operationen und DTOs umzugehen, funktioniert gut, solange die Business Logik, die auf diese Daten und Operationen angewandt werden soll, gering ist.
Die Nachteile:
- Oft kommt es zu Fehlanpassungen zwischen den Lese- und Schreibdarstellungen der Daten; zum Beispiel zusätzliche Spalten oder Eigenschaften, die korrekt aktualisiert werden müssen, obwohl sie nicht als Teil einer Operation benötigt werden.
- Viele Nutzer, die parallel auf die Datenbank zugreifen, steigern die Gefahr, dass die Integrität der Daten nicht gewährleistet werden kann. Die ausgiebige Nutzung von Transaktions-Mechanismen des RDBMS, sind unumgänglich. Die Performance der Applikation wird dadurch nicht steigen und die Komplexität der Querys nimmt zu.
- Die Verwaltung der Sicherheit und Berechtigungen werden umständlicher, da jede Entität sowohl Lese- als auch Schreiboperationen unterliegt, die versehentlich Daten im falschen Kontext ausliefern können.
Lösung
CQRS trennt die Lese- und Schreiboperationen und nutzt dafür unterschiedliche Interfaces. Dadurch kann sogar eine Trennung der data models erfolgen (nicht verwechseln mit den DTOs).
Durch Datenmodelle, die für Lese- bzw. Schreiboperationen optimiert wurden, kann die Komplexität der Implementierung reduziert werden. Ein Nachteil für einen Entwickler ist, dass mit diesen CQRS-Modellen nicht einfach Code generiert werden kann (getter/setter).
Diese Datenmodelle können die selbe physische Datenbank ansprechen, jedoch macht es aus Sicht der Sicherheit, der Performance und der Skalierbarkeit Sinn, auch die Datenbanken zu trennen.
Die Lese-Datenbank kann dann ein read-only-Duplikat der Schreib-Datenbank sein. Dadurch kann die Skalierung der Infrastruktur deutlich vereinfacht werden, da (meistens) deutlich mehr Leseoperationen in einer Applikation stattfinden, als Schreiboperationen. Das heißt, es können mehrere Lese-Datenbanken aufgesetzt werden, um so die Arbeitsgeschwindigkeit der Applikation zu erhöhen.
Außerdem kann die Lese-Datenbank und die Schreib-Datenbank dahingehend optimiert werden, dass diese verschiedene Normalisierungsgrade haben. Die Schreib-Datenbank kann zum Beispiel nach der dritten Normalform optimiert werden. Die Lese-Datenbank kann wiederum eine denormalisierte Datenbank verwenden, um möglichst schnelle Abfragen zu ermöglichen.
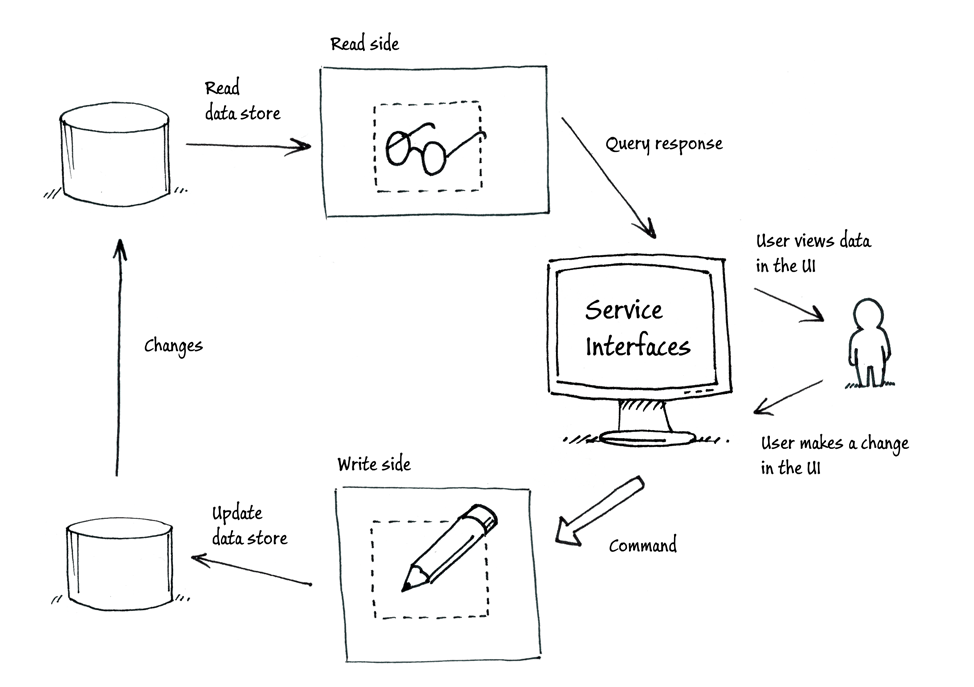 (Abbildung 1: Eine mögliche Implementierung des CQRS-Pattern. Quelle: https://msdn.microsoft.com/en-us/library/jj591573.aspx\)
(Abbildung 1: Eine mögliche Implementierung des CQRS-Pattern. Quelle: https://msdn.microsoft.com/en-us/library/jj591573.aspx\)
Wann sollte CQRS verwendet werden
- Wenn die Applikation den parallelen Zugriff mehrerer Nutzer auf die selben Daten ermöglicht und es häufig vorkommt.
- Wenn bei den Schreiboperationen viel Business-Logik auf die Daten angewandt wird und diese Daten immerzu validiert werden, um die Konsistenz der Daten zu gewährleisten. Das Lese-Modell gibt nur eine einfache DTO wieder und besitzt keinernei Business-Logik in diesem Fall.
- Wenn die Leseoperationen deutlich öfter stattfinden als Schreiboperationen und das Ziel der schnellere Zugriff auf die Daten ist.
- Wenn bei dem Entwicklungsprozess Entwickler-Teams mit unterschiedlichen Erfahrungswerten arbeiten. So kann das erfahrenere Team die komplexen Schreib-Modelle implementieren und das weniger erfahrenere Team implementiert die Lese-Modelle und kümmert sich um das User Interface.
Wann sollte CQRS nicht verwendet werden
- Wenn die Business-Logik relativ einfach ist.
- Wenn eine einfache Bedienoberfläche des CRUD-Typs und die damit verbundenen Datenzugriffsoperationen ausreichen.
- Wenn es sich um die Umsetzung durch das gesamte System handelt. Es gibt Komponenten in einem System, da kann die Implementierung des CQRS leichter sein. Diese sollten bevorzugt umgesetzt werden. Unnötige Komplexität sollte vermieden werden.