Pipes and Filters Pattern
Eine Aufgabe sollte aus mehreren einzelnen Schritten bestehen. Diese einzelnen Schritte sollten wiederwendbar sein. Diese Wiederverwendbarkeit verbessert die Leistungsfähigkeit, Skalierbarkeit und Wiederverwendbarkeit der einzelnen Schritte deutlich, da die einzelnen Schritte unabhängig und skalierbar untereinander sind.
Problem
Für die Entwicklung einer Anwendung kann man einzelne Verarbeitungsschritte zu einem monolithischen Modul zusammenfassen. Aber wenn die gleichen Verarbeitungsschritte in mehreren verschiedenen Modulen vorkommen, dann verbessert sich der Code nicht. Der Code wird dupliziert statt reduziert, da der Code nicht wiederverwendet wird, sondern nur kopiert wird. Der Code wird nicht gut optimiert, da der Code in verschieden Modulen dupliziert wird und keine Regeln der Wiederverwendbarkeit genutzt wurden. Die Anwendung ist dadurch nicht besonders skalierbar. Wenn sich einige Verarbeitungsschritte in den Modulen ändern z.B. der Ablauf der Schritte ändert sich oder weitere Schritte werden hinzugefügt, dann muss der Code an mehreren Stellen überarbeitet werden.
Lösung
Eine Lösung für diese Probleme wäre, wenn man die Verarbeitungsschritte zu einem Prozess zusammenfasst. Dieser Prozess verarbeitet die einzelnen Schritte linear. Die Verarbeitungsschritte erledigen immer eine Aufgabe. Jeder Verarbeitungsschritt empfängt Daten und sendet Daten an den nächsten Verarbeitungsschritt weiter. Die einzelnen Verarbeitungsschritte sind Komponenten. Diese Komponenten können einfach ausgetauscht werden, wenn sich der Prozess verändert. Außerdem wird duplizierter Code vermieden, da der Code in einer Komponente gekapselt ist. Ändert man den Code in der Komponente, so würgt sich diese Änderung auf alle Prozesse aus, wo diese Komponente verwendet wird. Das Prinzip führt zu einer besseren Wiederverwendung des Codes (siehe Abbildung 1).
Die Verarbeitungsgeschwindigkeit des Prozesses hängt von den einzelnen Komponenten ab. Wenn einige Komponenten zu langsam sind, dann kann das zu einer Verlangsamung des ganzen Prozesses führen. Aus diesem Grund sollte man parallele Prozesse verwenden, um die langsamen Komponenten zu verteilen. Diese Verteilung erhöht die Verarbeitungsgeschwindigkeit der Anwendung. Gerade bei Serveranwendungen führt, dass zu einer besseren Performance für das gesamte System. Die Komponenten (oder Filters) sind untereinander unabhängig und können beliebig skaliert werden. Sie eignen sich gut für Cloud-Server, da die Komponenten auf verschiedene Maschinen verteilt werden können. Rechenintensivere Komponenten können auf leistungsfähigeren Maschinen verteilt werden als weniger rechenintensivere Komponenten, dass spart kosten und führt zu einer besseren Performance für die Serveranwendung. Man kann von überall auf der Welt auf die Komponenten und Prozesse (oder auch Pipeline) zugreifen, da sich diese in der Cloud befindet.
Der vorige Filter kann seine Ergebnisse an den nächsten Filter in der Pipeline weitergeben, bevor der vorige Filter zu Ende ist. Es können so mehrere Filter parallel arbeiten. Sollte ein Filter oder eine Maschine von der Cloud ausfallen, dann kann die Pipeline diesen Fall kompensieren. Die Pipeline leitet die Verarbeitungsschritte an einem anderen Filter weiter. Dieser Filter erledigt dann diese Aufgaben und gibt das Ergebnis an der Pipeline zurück. Das System ist dadurch sehr gut gegen Systemausfälle geschützt, da bei ausfällen einer oder mehrere Filters nicht diese ganze Pipeline mit ausfällt. Wenn man verteilte Transaktionen entwickeln will, dann kann man das „Pipes and Filters Patterns“ mit dem „Compensating Transaction Pattern“ kombinieren. Die verteilte Transaktion wird in mehrere Aufgaben geteilt und jede Aufgabe bekommt einen Filter. Der Filter benutzt das „Compensating Transaction Pattern“.
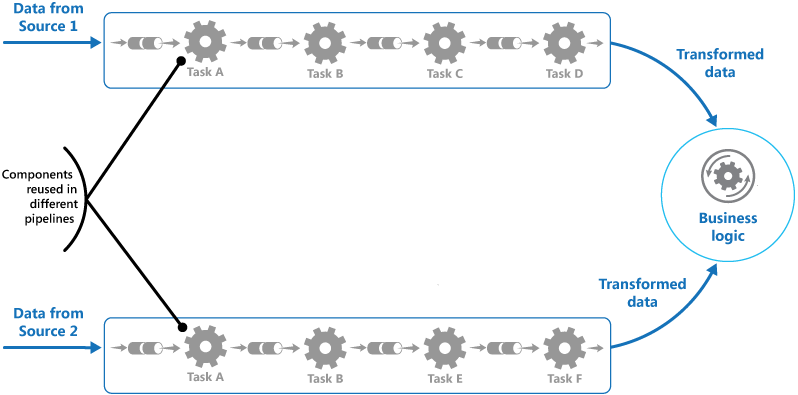
Abbildung 1: Grafische Darstellung des Patterns.
Benutzung
Wenn man das „Pipes and Filters Patterns“ benutzen will, dann sollte man darauf achten, dass die Anwendung nicht Komplexer dadurch wird, immer noch zuverlässig läuft, das keine Idempotenz entsteht, keine wiederholten Nachrichten verschickt werden und der Zustand und Kontext der Filter erhalten bleibt. Eine Komplexität kann dadurch entstehen, wenn man die Aufgaben an verschiedene Server verteilt. Die Zuverlässigkeit muss sicherstellen, dass keine Daten zwischen den einzelnen Filters verschwinden. Filters sollten Idempotenz sein, da sonst Ergebnisse von verschiedenen oder gleichen Filtern mehrfach auftreten könnten. Diese Daten würden dann mehrfach verarbeitet werden, dass führt zu Leistungseinbrüchen der Serveranwendung. Die Pipeline muss überprüfen, ob doppelte Nachrichten an die Filters geschickt werden und gegebenenfalls diese entfernen. Jeder Filter muss seinen Zustand speichern und seinen eigenen Kontext besitzen, da sie getrennt voneinander arbeiten.
Anwendungsbeispiele
Zum Beispiel geeignet für folgende Aufgaben:
- Ein Problem in mehreren unabhängigen Schritte lösen
- Die Verarbeitungsschritte der Serveranwendung sind unterschiedlich skalierbar
- Wenn etwas Flexibel ist, dann kann man die Verarbeitungsschritte anders anordnen und untereinander verändern
- Die Verteilung der Serveranwendung und der Verarbeitungsschritte auf viele verschiedenen Servers verbessert die Leistung für die Serveranwendung
- Wenn ein System vor Ausfällen geschützt werden soll
Es ist nicht so gut geeignet für folgende Aufgaben:
- Wenn die Verarbeitungsschritte nicht unabhängig voneinander sind, sondern zu einem großem Zusammenhang gehören.
- Wenn die Speicherung der Zustandsinformation Probleme mit der Datenbank verursachen würde
Bei der Implementierung sollte eine Warteschlange für die Pipeline verwendet werden. Die Filter bekommen die Daten und verarbeiten die Daten danach. Wenn die Daten verarbeitet wurden, dann werden die Daten an dem nächsten Filter in der Warteschlange weitergeben. Bis das Ende der Warteschlange erreicht wurde. Der Anfang macht das erste Objekt der Filter Klasse in der Warteschlange.