Knowledge Discovery in Databases (KDD)
Das Volumen der jährlich generierten digitalen Datenmenge ist in den letzten Jahren massiv angewachsen. Doch nur eine geringe Menge dieser Daten wird für Analysen genutzt.[5] Knowledge Discovery in Databases beschreibt das generelle Vorgehen, um genau diese Daten zu nutzen, dass heißt Wissen zu generieren.
Definition
Der Begriff Knowledge Discovery in Databases wird in der Literatur unterschiedlich verwendet. Es kommt vor, dass es als Synonym zu dem Begriff Data Mining genutzt.[4] Üblicherweise beschreibt Knowledge Discovery in Databases aber einen Prozess in dem Data Mining lediglich einen Teilschritt darstellt.[2]
Das Gabler Wirtschaftslexikon definiert KDD wie folgt:
Knowledge-Discovery-in-Databases (KDD)-Prozess; umfassender Datenanalyseprozess, in dessen Kern Verfahren des Data Mining zur Anwendung kommen. Der-Knowledge-Discovery-in-Databases (KDD)-Prozess umfasst folgende Phasen:[...] [3]
Hung (2009) beschreibt KDD als einen:
[...] nichttrivialer mehrstufiger Prozess der Wissensfindung aus vorhandenen Informationen. KDD-Prozess umfasst alle Schritte, von woher die Daten abgeholt werden, über Vorverarbeitung und eigentliche Verarbeitung zur Informationsgewinnung (Data-Mining-Schritt), bis hin wie die Endinformation interpretiert und dargestellt wird. [2]
KKD-Prozess
Fayyad et al. beschrieben 1996 erstmals die einzelnen Schritte, die bei der Knowledge Discovery in Databases genutzt werden. Dazu entwickelten sie ein Model, welches heutzutage oft unter den Begriffen "KDD Prozess" oder "Schritte des KDD" zu finden sind.
Nach Fayyad et al. besteht KDD aus den folgenden neun Schritten:[1]
- Problemabgrenzung
- Auswahl der Daten
- Datenvorverarbeitung
- Datenreduktion und Kodierung
- Auswahl der Data Mining Methode
- Auswahl des Data Mining Algorithmus
- Data Mining
- Interpretation der Ergebnisse
- Anwendung des gefundenen Wissens
Das Fayyad Modell des KDD Prozesses ist in Abbildung 1 dargestellt. Es handelt sich im ein iteratives Modell, dass bedeutet, die Schritte können mehrfach durchlaufen werden. Nach der Evaluation der Ergebnisse müssen eventuell einige Schritte neu durchlaufen werden, um das Ergebnisse in der Evaluation zu verbessern. So kann es beispielsweise sein, dass in der Evaluation auffällt, dass bei der Vorverarbeitung nicht alle unerwünschten Daten herausgefiltert wurden.[1][2]
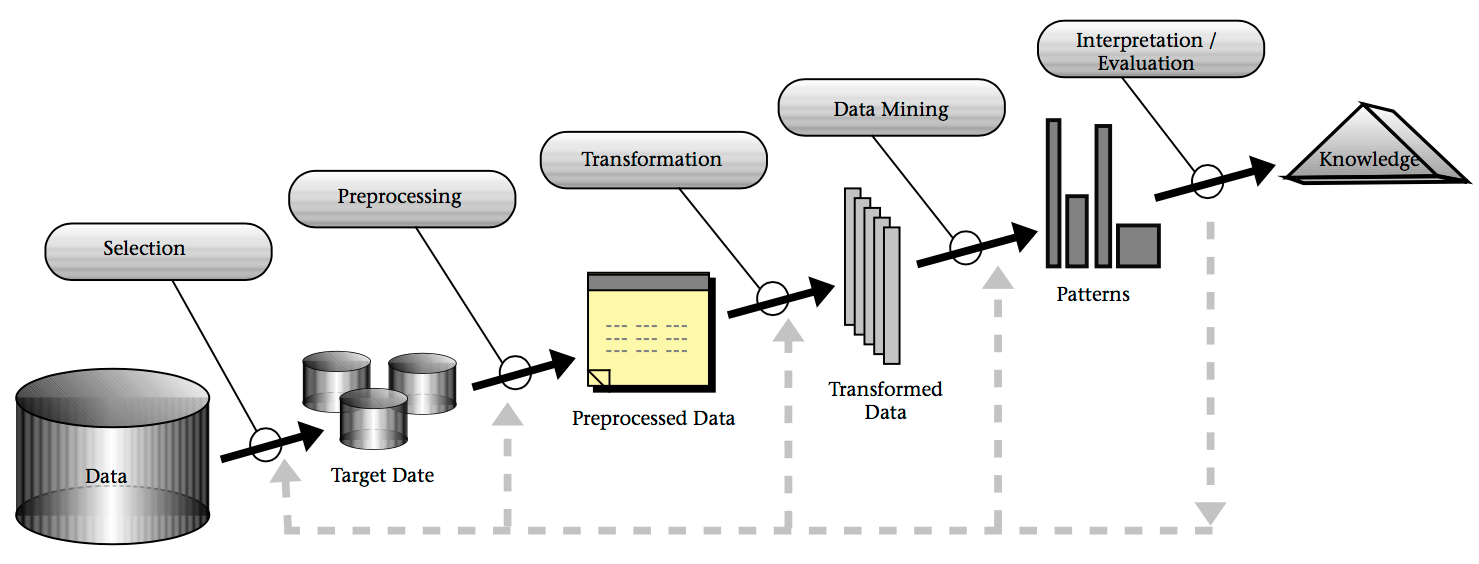 Abbildung 1: Fayyad Modell des KDD Prozesses[1]
Abbildung 1: Fayyad Modell des KDD Prozesses[1]
Die Schritte im Detail
1. Problemabgrenzung: Im ersten Schritt muss zunächst das Ziel aus der Sicht des Kunden identifiziert werden. Außerdem ist es wichtig sich mit dem jeweiligen Fachbereich vertraut zu machen.[1]
2. Auswahl der Daten: Im zweiten Schritt wird ein Datensatz ausgewählt. Das Ziel aus Schritt eins sollte dabei beachtet werden, denn das erreichen des Zieles hängt von der Qualität des Datensatzes ab.[1]
3. Datenvorverarbeitung: Im dritten Schritt werden die Daten vorverarbeitet. Unerwünschte Informationen, die die Ergebnisse des Data Minings negativ beeinflussen würden, sollten herausgefiltert werden. In diesem Schritt sollte auch entschieden werden, wie mit fehlenden/unvollständigen Datenfeldern umgegangen wird.[1]
4. Datenreduktion und Kodierung: Im vierten Schritt werden die Daten in eine andere Form überführt, damit Data Mining Algorithmen sie verstehen und verarbeiten können. Dieses Verfahren wird oft auch "Kodierung", "Datenprojektion" oder "Datentransformation" genannt. Bei der Datentranformation wird i.d.R. auch eine Datenreduktion durchgeführt, bei der Daten mit geringer Aussagekraft entfernt werden. [1]
5. Auswahl der Data Mining Methode: Im fünften Schritt wird mit Hilfe des Ziels aus Schritt 1 eine bestimmte Data Mining Methode ausgewählt. Bekannte Methoden sind beispielsweise die Klassifikation oder die Clusteranalyse.[1]
6. Auswahl des Data Mining Algorithmus: Im sechsten Schritt wird innerhalb der zuvor gewählten Data Mining Methode ein Algorithmus ausgewählt. Zudem wird entschieden mit welchen Parametern dieser Algorithmus am besten aufgerufen wird.[1]
7. Data Mining: Der siebte Schritt ist das eigentliche Data Mining.[1]
8. Interpretation der Ergebnisse: Im achten Schritt werden die Ergebnisse des Data Minings interpretiert. Dies kann auch eine Visualisierung umfassen.[1]
9. Anwendung des gefundenen Wissens: Im neunten Schritt werden die Ergebnisse angewendet. Das bedeutet beispielsweise das Wissen in ein anderes System weiter zu geben, oder auch einfach eine Dokumentation der Ergebnisse anzufertigen. Weiter sollte auf Konflikte zu dem bisherigen Wissensstand geprüft werden.[1]
Einordnung dieses Projektes in den KDD Prozess
Dieses Projekt "Twitter-Miner" durchläuft alle Schritte des KDD Prozesses. In diesem Kapitel soll ein kurzer Überblick gegeben werden, was in diesem Projekt in den jeweiligen Schritten gemacht wurde und wo weitere Informationen zu finden sind.
1. Problemabgrenzung: Die Problemabgrenzung und Definition des Ziels wurde u.a. im Pflichtenheft festgelegt. Ziel ist die Stimmungsanalsyse von Tweets (=Sentiment Analysis).
2. Auswahl der Daten: Die Datenbasis dieses Projektes bilden Tweets. Zu einem bestimmten Hashtag werden über eine Schnittstelle Tweets geladen.
3. Datenvorverarbeitung: Tweets können viele unerwünschte Informationen enthalten wie beispielsweise Links, die in diesem Schritt entfernt werden. Weiteres zum Thema Datenvorverarbeitung ist hier zu finden.
4. Datenreduktion und Kodierung: Um die Tweets als Eingabe für unsere Data-Mining-Algorithmen zu nutzen wurden sie in entsprechende Zahlenrepräsentationen umgewandelt. Innerhalb dieses Projektes wurden dafür sogenannte tf-idf Vektoren genutzt. Dieses Thema wird ebenfalls in diesem Kapitel beschrieben.
5. Auswahl der Data Mining Methode: Das Ziel aus Schritt 1 (Sentimentanalyse) lässt sich mit der Data Mining Methode "Klassifikation" erreichen. Kassifikationsalgorithmen können bestimmen, ob ein Merkmal zu einer bestimmten Klasse gehört oder nicht. Das heißt bei der Sentimentanalyse gibt der Klassifikationsalgorithmus aus, ob es sich um einen positiven Tweet oder einen negativen Tweet handelt.
Eine generelle Übersicht der Data Mining Methoden ist hier aufgelistet.
6. Auswahl des Data Mining Algorithmus: Innerhalb dieses Projektes werden die drei folgenden Klassifikationsalgorithmen genutzt.
7. Data Mining: In diesem Schritt wird ein Datensatz auf mehrere Tweets mit den Algorithmen aus Schritt 6 klassifiziert.
8. Interpretation der Ergebnisse: Die Ausgabe der Algorithmen wird in diesem Schritt interpretiert. Ist die Ausgabe beispielsweise [0,1], so ist der entsprechende Tweet positiv, ist die Ausgabe [1,0], so ist er negativ.
9. Anwendung des gefundenen Wissens: Die Anwendung des gefundenen Wissens erfolgt in einer Präsentation durch eine Weboberfläche.
1. Fayyad, U., Piatetsky-Shapiro, G., & Smyth, P. (1996). From Data Mining to Knowledge Discovery in Databases. AI Magazine, 17(3), 37. ↩↩↩
2. Hung, P. T. (2009). Data-Mining und Knowledge Discovery in Databases (KDD) Ein Überblick. Dresden. Retrieved from https://www.inf.tu-dresden.de/content/institutes/iai/tis-neu/lehre/archiv/folien.ws_2008/Vortrag_Hung.pdf ↩↩↩
3. Springer Gabler Verlag (Herausgeber), Gabler Wirtschaftslexikon, Stichwort: Knowledge Discovery in Databases (KDD), online im Internet: http://wirtschaftslexikon.gabler.de/Archiv/75635/knowledge-discovery-in-databases-v10.html ↩
4. Alpaydın, E. (2014). Introduction to machine learning. Methods in Molecular Biology (Second Edi, Vol. 1107). The MIT Press.↩
5. Gantz, John und David Reinsel (2012). IDC IVIEW: THE DIGITAL UNIVERSE IN 2020: Big Data, Bigger Digital Shadows, and Biggest Growth in the Far East. Techn. Ber. URL: http://www.emc.com/collateral/analyst-reports/idc-the-digital-universe-in-2020.pdf ↩
Author: Daniel Beneker