GraphQL
GraphQL ist eine Abfragesprache für strukturierte Daten, welche 2012 von Facebook entwickelt und 2015 anschließend veröffentlicht wurde (vgl. GraphQL 2017). Ziel von GraphQL ist es, die Datenübermittlung zwischen Server und Client einfacher und effizienter zu gestalten. Neben der Referenz-Implementierung in JavaScript existieren Bibliotheken für andere Programmiersprachen, wie beispielsweise C#, Java oder Python.
Probleme von REST
Dienste, die streng nach dem Architekturstil REST aufgebaut sind, können zum Flaschenhals für eine Client-Server-Interaktion werden. Dies beruht nach (Facebook 2015) auf drei Tatsachen.
Starrheit der Daten: Ein RESTful Dienst legt statisch fest, welche Ressourcen bzw. Repräsentationen angefragt werden können. Er spezifiziert dazu jeweils die URIs, auf die sich der Client beziehen muss, sowie die Operationen, die ausgeführt werden können. Folgendes Szenario verdeutlicht dabei ein mögliches Problem (siehe Abbildung 10). Der Client möchte beispielsweise wissen, mit welchem Wetter eine bestimmte Person morgen bei der Arbeit rechnen muss. Der Server bietet ihm dafür drei Endpunkte, mithilfe der er Personen, Arbeitgeber und Standorte abfragen kann. Um seine Ausgangsfrage zu beantworten, muss der Client nun drei verschiedene Anfragen absenden und jeweils auf die Ergebnisse warten. Dieser erhöhte Aufwand resultiert daher, dass der Server keinen Endpunkt anbietet, anhand dessen die Problemstellung innerhalb lediglich einer Anfrage bzw. Antwort gelöst werden kann. Eine REST-API zu konstruieren, die auf jede nur mögliche verschachtelte Anfrage innerhalb einer Nachricht antwortet, ist für mittlere bis große Dienste nicht machbar.
 Abbildung 10: Mehrmaliges Anfragen als Nachteil von REST
Abbildung 10: Mehrmaliges Anfragen als Nachteil von REST
Fehlende Versionierung: Die Server-Komponenten eines RESTful Dienstes entwickeln sich kontinuierlich weiter. Insbesondere die Ressourcen bzw. Repräsentationen unterliegen dabei häufig Veränderungen in Form von neuen Datenfeldern. In der Regel greifen jedoch heterogene Clients auf den Dienst zu, welche sich im Hinblick auf ihre Bedürfnisse voneinander unterscheiden. Manche von diesen Benutzern benötigen beispielsweise die hinzugefügten Datenfelder als Antwort auf ihre Anfrage, während die Datenfelder für ältere Clients keine Bedeutung haben könnten und nur zusätzlicher Ballast sind. Dadurch bedingt, dass der Server lediglich einen Endpunkt für jede Ressource anbietet, erhalten alle Clients dieselbe Version der Repräsentation. Auf individuelle Ansprüche wird somit keine Rücksicht genommen.
Schwache Typisierung: RESTful Services empfangen Informationen häufig in der Form von JSON- oder XML-Dokumenten. Diese müssen lediglich eine bestimmte Syntax erfüllen, um vom Server akzeptiert zu werden. Einzelne Datenfelder innerhalb der Dokumente sind jedoch nur schwach typisierbar. Für den Server bedeutet es daher einen erheblichen Mehraufwand, jede übermittelte Repräsentation auf ihre semantische Korrektheit zu überprüfen.
Abhilfe
Ein GraphQL-Server wird von jedem Client und unabhängig von den angefragten Daten über denselben Endpunkt erreicht (siehe Abb. 11). Weiterhin unterscheidet der Server nicht zwischen den Aufrufoperationen. Geschieht die Client-Server-Kommunikation über HTTP, führt der Client beispielsweise nur POST-Anfragen an eine bestimmte URI durch. Die Semantik der Anfrage ist dabei ausschließlich innerhalb des Bodies definiert.
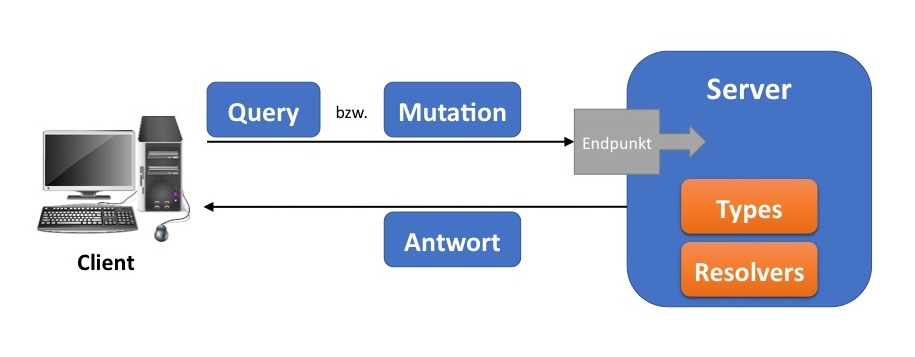
Abbildung 11: Schaubild GraphQL
Anfragen, die dem Client lediglich Daten übermitteln sollen, werden innerhalb einer sogenannten Query formuliert (analog zu GET-Anfrage). Ist eine Manipulation der serverseitigen Daten gewollt, muss eine Mutation übermittelt werden (analog zur POST-, PUT- und DELETE-Anfrage). Zur Verarbeitung von Queries und Mutations besitzt der Server Types und Resolvers. (vgl. GraphQL 2017)
Query
Eine Query veranlasst eine Datenübermittlung vom Server zum Client. Der Client bestimmt dabei dynamisch, welche Informationen er erhalten möchte. Er kann somit nicht nur das Objekt eingrenzen, das übermittelt werden soll, sondern zusätzlich die Datenfelder selektieren.
Besitzt ein Objekt Auto beispielsweise die Attribute Hersteller, Modell, Leistung, Hubraum, Sitzanzahl und Preis, kann der Client explizit mitteilen, welche Datenfelder er tatsächlich benötigt (siehe Code-Beispiel 5). Eine Query hat dementsprechend immer dieselbe Form, wie die zugehörige Antwort. Weiterhin ist es möglich, eine Query beliebig tief zu verschachteln. Ist das Datenfeld eines Objekts wiederum ein Objekt, können auch hier Datenfelder selektiert werden.
# Query an den Server
query AllgemeineInformationenZuAuto455{
auto(id: "455") {
hersteller{
name
standort
}
modell
leistung
hubraum
}
}
# Antwort vom Server:
{
"data": {
"auto": {
"hersteller": {
"name": "vw",
"standort": "wolfsburg"
},
"modell": "golf",
"leistung": "150",
"hubraum": "2"
}
}
}
Code-Beispiel 5: Statische GraphQL-Query mit passender Antwort
Variablen
Der bisherige Ansatz hat den Nachteil, dass Parameter fest mit der Query verknüpft sind. Sollte im vorherigen Beispiel ein Auto mit der Identifikationsnummer 499 abgefragt werden, ist der komplette Query-String zu verändern bzw. eine komplett neue Query zu spezifizieren. Um Queries generisch nutzen zu können, dienen Variablen (siehe Code-Beispiel 6). Innerhalb der Anfrage werden alle dynamischen Parameter durch Platzhalter ersetzt. Abhängig vom eingesetzten Protokoll erfolgt die Auflösung der Variablen in einem separaten Wörterbuch. Eine Anfrage muss somit lediglich einmalig erzeugt werden, während das Wörterbuch dynamisch anzupassen ist.
# Query an den Server
query HerstellerinformationenZuEinemBestimmtenAuto($id: ID){
auto(id: $id) {
hersteller
modell
}
}
# Wörterbuch an den Server
{
"id": "499"
}
# Antwort vom Server
{
"data": {
"auto": {
"hersteller": "fiat",
"modell": "500"
}
}
}
Code-Beispiel 6: Variable GraphQL-Query in Verbindung mit Wörterbuch und passender Antwort
Direktiven
Um Queries noch generischer formulieren zu können, dienen Direktiven (siehe Code-Beispiel 7). Jedes angefragte Datenfeld kann um ein @include(if: Boolean) bzw. @skip(if: Boolean) ergänzt werden. Soll ein Datenfeld bei einer bestimmten Bedingung beispielsweise nicht angefragt werden, ist ein @skip(if: $Bedingungsvariable) anzuhängen. Dieselbe Query kann somit in Abhängigkeit des Wörterbuchs für verschiedene Zwecke genutzt werden.
# Query an den Server
query AllgemeineInformationenZuEinemBestimmtenAuto($id: ID, $preisangabe: Boolean){
auto(id: $id) {
hersteller
modell
preis @include(if: $preisangabe)
}
}
# Wörterbuch an den Server
{
"id": "1"
"preisangabe": true
}
# Antwort vom Server
{
"data": {
"auto": {
"hersteller": "mercedes",
"modell": "a-klasse",
"preis": 20000
}
}
}
Code-Beispiel 7: GraphQL-Query mit Variablen und Direktive
Mutation
Das Pendant zu der Query bildet die Mutation. Immer wenn Daten auf Seiten des Servers generiert, aktualisiert oder gelöscht werden sollen, ist diese Art der Anfrage zu übermitteln. Der Aufbau einer Mutation ähnelt dabei dem einer Query. Es kann ebenfalls eine beliebig tiefe Verschachtelung der Anfrage erfolgen. Auch Variablen und Direktiven sind nutzbar. Lediglich das Schlüsselwort query ist in mutation zu ändern.
Types
Types liegen im Server vor und bilden die Kommunikationsgrundlage zwischen Server und Client. Hierunter sind die logischen Datenmodelle zu verstehen, auf denen Queries und Mutations arbeiten. Jeder sogenannte GraphQL Object Type beinhaltet eine Menge von Attributen (siehe Code-Beispiel 8). Dies können zum einen Skalare sein, die keine weitere Auflösung erlauben. Von GraphQL bereitgestellte Skalare sind Int, Float, String, Boolean und ID. Auch GraphQL Object Types können als Attribute vorliegen, wenn sie an anderer Stelle definiert werden. Weiterhin erlaubt GraphQL Listentypen sowie die Deklaration eigener Aufzählungen. Spezielle Typen sind hingegen der Query bzw. Mutation Type. Mithilfe dieser kann spezifiziert werden, welche Objekte seitens des Clients abgerufen bzw. manipuliert werden können. Sie bilden damit den Einstiegspunkt für jede passende Anfrage.
# Serverseitiges Datenschema
# Einstiegspunkte für Queries
type Query {
# Client kann Auto-Objekt anhand von ID abrufen
auto(id: ID!): Auto
}
type Mutation {
...
}
type Auto {
# Hersteller darf nicht null sein
Hersteller: Hersteller!
Modell: String
Hubraum: Int
Antrieb: AntriebEnum
# Liste von Vorbesitzern
Vorbesitzer: [String]
}
type Hersteller {
Name: String
Standort: String
}
enum AntriebEnum {
Allrad
Hinterrad
Vorderrad
}
Code-Beispiel 8: Serverseitige Definition von Object Types
Resolvers
Types definieren den Aufbau von einzelnen Datentypen. Durch Kenntnis dieser Struktur kann der Server entscheiden, ob eingehende Anfragen valide sind oder das Schema verletzen. Um Antworten zu generieren, sind Types jedoch nicht ausreichend. Es muss zwangsläufig ein Bezug zwischen der Struktur der Daten und ihrer tatsächlichen Lage hergestellt werden. Hierzu dienen sogenannte Resolvers (siehe Code-Beispiel 9). Ein Resolver ist eine Funktion (in diversen Sprachen implementierbar), die der Server aufruft, wenn ein spezifisches Datenfeld zurückgeliefert werden muss. Der Inhalt der Funktion wird durch die Geschäftslogik des Serverdienstes definiert und ist demnach eigenhändig zu implementieren. Typischerweise wird bei eingehender Anfrage der Root Resolver aufgerufen. Dieser liefert das Ausgangsobjekt (im aktuellen Beispiel ein Auto) zurück. Abhängig von den angefragten Datenfeldern werden auf diesem Objekt weitere Resolver aufgerufen, die zusätzliche Daten beschaffen. Die ermittelten Informationen werden nach Abschluss der Routine geeignet zusammengefügt und an den Client übermittelt.
# Resolver-Beispiel-Implementierung in JavaScript
# Root Resolver
Query: {
auto(obj, args, context) {
return context.meineDatenbank.ladeAutoAnhandID(args.id).then(
data => new Auto(data)
)
}
}
# Aufgerufen, wenn Auto-Objekt bereits vorhanden
Auto: {
hersteller(obj, args, context) {
return context.meineDatenbank.ladeHerstellerAnhandID(obj.herstellerID).then(
data => new Hersteller(data)
}
modell(obj, args, context) {
return obj.modell
}
...
}
...
Code-Beispiel 9: Serverseitige Definition von Resolvers
Best Practices
GraphQL ist lediglich eine Abfragesprache und gibt keine Implementierungs- bzw. Nutzungsrichtlinien vor. Dennoch existiert nach (GraphQL 2017) eine Reihe von Best Practices, die im Folgenden skizziert werden.
- HTTP: GraphQL-Anfragen und -Antworten können theoretisch über jedes Netzwerkprotokoll übermittelt werden. Aufgrund seiner Verbreitung ist jedoch das Hypertext Transfer Protocol zu bevorzugen. Der Dienst wartet dabei typischerweise unter dem Pfad /graphql auf Anfragen seitens des Clients. Queries und Mutations können weiterhin sowohl im Body eines POST-Requests als auch in der Query eines GET-Requests übergeben werden. Unabhängig davon, ob eine Query oder eine Mutation versendet wurde, antwortet der Server idealerweise mit dem angefragten bzw. dem manipulierten Datenobjekt. Auch Fehlermeldungen werden im Body der Antwort übergeben.
- JSON: Vom Server übermittelte Daten befinden sich zwecks Lesbarkeit stets in der JavaScript Object Notation.
- Keine Versionierung: Der Client spezifiziert bei jeder Anfrage, auf welche Datenfelder er sich bezieht. Dies macht eine Versionierung des GraphQL-Dienstes überflüssig.
- Caching: Im Gegensatz zu REST ist Caching bei GraphQL-Diensten nicht über die URI einer Anfrage möglich. Serverseitiges Caching kann dennoch betrieben werden, wenn jedes Objekt durch eine global eindeutige ID identifiziert wird. Häufige Datenbankzugriffe sind somit vermeidbar, was in einer Performanzsteigerung des Dienstes resultiert.
Zusammenfassung
Die Grundprinzipen von GraphQL werden abschließend nach (Facebook 2015) zusammengefasst.
- Hierarchisch: Anfragen sowie Datenmodelle sind hierarchisch aufgebaut. Ein Kernelement wird dabei immer weiter in seine Grundbestandteile zerlegt, bis ausschließlich Skalare vorliegen. Dies unterstützt sowohl Entwickler als auch Anwender bei ihrer Arbeit.
- Produktbezogen: Im Mittelpunkt von GraphQL stehen die Daten bzw. deren Benutzer.
- Clientspezifische Anfragen: Der Client bestimmt dynamisch, welche Daten er benötigt bzw. welche Daten für ihn gegenstandslos sind. Der Server richtet sich vollkommen nach dem Client.
Rückwärtskompatibilität: Jede Clientversion kommuniziert mit demselben Endpunkt und beschafft sich ihre benötigten Daten.
Beliebige Datenbeschaffung: Der Server bestimmt für jedes einzelne Datenfeld seine eigene Beschaffungsroutine, ohne dabei von bestimmten Technologien abhängig zu sein.
Applikationsschicht: GraphQL ist in der Applikationsschicht angesiedelt und muss sich daher nicht um den Transport von Daten kümmern, sondern lediglich um deren Verarbeitung.
Stark typisiert: Queries und Mutations können vom Server effizient hinsichtlich Semantik und Syntax validiert werden.
Selbstbeschreibend: GraphQL-Anfragen und -Datenmodelle werden in einem eigenen Format beschrieben. Hierdurch erhöht sich die Unabhängig zu anderen Systemen und Programmiersprachen.